Sample articles that has to do with DATABASESFeatured Database ArticlesMS AccessDecember 7, 2009
Database Table and Field Naming SuggestionsBy Danny Lesandrini
I chose this topic because it sounded fun but I know it's the kind of thing that could start a holy war among developers and DBAs. After all, who am I to tell anyone how they should name tables and fields? Actually, I'm not the worst choice for advice on naming schemas. It's something I've thought a lot about over the last 14 years.
Some of my naming standards were handed to me on a silver platter by kindly developers with more experience than I had and some were earned the hard way. I can say from personal experience that it's better to receive these lessons free than earn them. Consider some examples. We'll start with field naming.
Field Naming: The Dos and Don'tsMicrosoft Access is a great product that allows you to do practically anything when it comes to naming. It's my opinion that Access was originally written with Excel power users in mind. I think that somewhere in the mid 90's it was hijacked by programmers and taken to levels that Microsoft never intended. It's precisely this feature, field naming, that makes me feel this way. Hard-core developers would never dream of naming things the way Access allows for.
Below is a screen shot of a table I created in Access, which I appropriately named BAD_table. It encapsulates a number of bad practices that I see all the time when I assist clients with Access database applications that were built in-house by people who could probably be described as Excel Power Users.
They know enough to be dangerous, but they don't know why. If you're an Excel Power User, you might be feeling the hairs on the back of your neck stand on end as you read this, but stick with it for another couple paragraphs and you'll understand what I mean. The problems that come from bad naming conventions don't manifest themselves until one begins writing code but by then it's too late to change them.
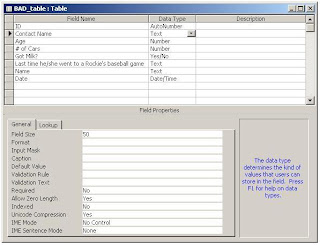
So, what's wrong with these field names?
[ID]
There's technically nothing wrong with naming a field [ID] but once you start creating queries, you'll find that this is too ambiguous and you'll wish you'd named them differently. Consider this SQL statement.
SELECT * FROM tblContact c
INNER JOIN tblEmployee e ON e.ID = c.EmployeeID
INNER JOIN tblStatus s ON s.ID = c.StatusID
All three of these tables have a primary key field named [ID] but when these ID fields show up as foreign keys in other tables, their names must be changed. Thus you get links that read ID=EmployeeID and ID=StatusID instead of EmployeeID=EmployeeID and StatusID=StatusID. Some will write to tell me that this doesn't end up being as confusing as I'm making it out to be but I've been there, done that, and it's my suggestion that you avoid this approach.
[Contact Name]
There are potentially two things wrong with this field name. First, one might split this field into [ContactFirstName] and [ContactLastName], though an equally good argument might be made for keeping them together. It's just that sometimes you might want to display a name as First-Last and sometimes as Last-First. If you use only one field for the full name, you forfeit that flexibility.
The second problem, which we see a lot of, is the embedded space. Access allows you to do this, even though you will curse the day you added spaces once you start coding. It may seem like a little thing, but I've written so many thousands of lines of code that I start looking for shortcuts when typing. If you have spaces, you'll simply have to do more typing.
For example, consider this code for accessing fields in a DAO recordset:
sSQL = "SELECT FirstName, [Birth Date] FROM tblContacts"
Set rst = dbs.OpenRecordset(sSQL, dbOpenSnapshot)
Debug.Print rst!FirstName
Debug.Print rst![Birth Date]
The extra typing I'm referring to is the set of square brackets. You must add them to both the SQL statement and to the recordset field assignment. It gets more funky when you start creating forms with the wizard, which will name the associated text box Birth Date like the field. At least it appears to. Behind the scene, it uses an underscore for the space, so the control is referenced as Birth_Date. This can be seen in the event sub procedure assignments. For example, the after update event of the [Birth Date] field would be ...
Private Sub Birth_Date_AfterUpdate()
I guess the point is that it's not necessary to add spaces and contributes nothing except more typing. Access allows you to supply a caption for a field, which automatically provides for a readable alias when the field is added to a query. If you want spaces, update the Caption property but don't put them in the actual field names.
[# of Cars] and [Got Milk?]
Everything mentioned above about spaces applies equally well to special characters, although there are some special characters that Access won't allow you to use, namely . ! [ ]. These characters mean something in SQL Statements. While the pound sign and question mark are not operators and may be used, they present other problems, as does starting a field with a number.
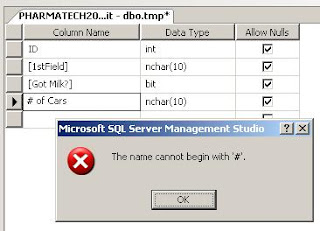
Below is a screen shot of a table I tried to create in SQL Server. Notice that I succeeded in creating a field that begins with a number, namely [1stField]. The brackets were added automatically by SQL Server as a quiet protestation to the name. In fact, SQL Server 7 didn't even allow field names that began with a number. In my example below, [Got Milk?] is allowed with the question mark provided the field is bracketed but it choked on the pound sign.
So while Access will allow me to name a field as [# of Cars], SQL Server will not. That means that in addition to making my code more complicated, this Access table cannot be upsized to SQL Server, should that whim ever strike me.
[Last time he/she went to a Rockie's baseball game]
My spell checker now tells me that Rockie's isn't correct, which is the first thing wrong with this field name. J The next is the spaces and special characters. In fact, I'm not sure why a single quote is allowed. That's going to wreak havoc in SQL Statements, I'm sure. I don't like the foreword slash either, though I can't say exactly what harm it may or may not do.
The real problem is the length of this field name. Somehow, there has to be a balance between too much abbreviation and too many words. Do you really want to have to type a field name that big? On the other hand, simply removing the spaces and vowels is no better. Who could decipher a field named LstTmHShWntTRckysBsbllGm. In my GOOD_table below, you see I renamed this field to BaseballNote. That's a good compromise: self-explanatory enough and not too verbose.
[Name] and [Date]
For these last two, it's probably not so obvious as to why I object. Try this as an experiment. Open any Access database and press Ctl+G to bring up the immediate window. (Bottom of the VBA environment window.) Now type a question mark and one of these field names, and then hit the ENTER key. Below are the results of these two field names, and other potentially poor choices.
?Name
Microsoft Access
?Date
7/30/2009
?Now
7/30/2009 9:42:20 AM
?CurrentUser
Admin
These words represent built-in functions within Microsoft Access. The Date() function returns today's date. Now while you are allowed to create a field named [Date] it means you might end up writing SQL that looks like this ...
SELECT * FROM tblOrders WHERE Date=Date()
Does this SQL break? Not that I know of but it lends itself to ambiguity. The question is, why would you want a field named [Date]? What date is it? OrderDate or ShipDate? If you have a field named [Name], what name is it? Person name or product name or what?
Below is a screen shot of the corresponding GOOD_table. The ID field is not ambiguous, spaces are removed and no special characters were used. The field names are descriptive, yet short enough to be reasonable when typed. There's one other subtle but important difference between this screen shot and the previous table image. Can you see it?
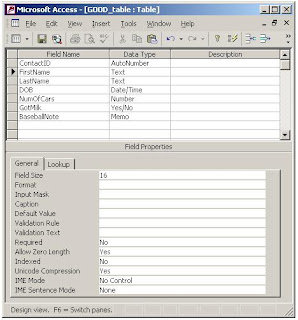
Here's where I have to give credit to a great programmer-friend of mine, Jim Pilcher. It was nearly a decade ago when I did some work for him that he introduced me to his rule-of-thumb for sizing text fields, and I'm going to share it with you here.
Notice above in the BAD_table that the [Contact Name] field is 50 characters. What this tells you is that I accepted the Access default size and probably didn't think about what size it should really be. Now perhaps 50 characters represents 20 for First Name and 30 for Last Name, or maybe 25 for each ... or maybe I just didn't think about it at all. There's no way to know for sure.
Jim's convention when choosing field size is to use a binary value, 2 to the power of something. With this plan, field sizes will always be in this list: 1, 2, 4, 8, 16, 32, 64, 128, 255. (Access doesn't allow fields of size 256 because it needs the last bit for its own purposes.) I've added 48 and 96 to that list even though they are not powers of 2, because I like those sizes for certain fields. Have you figured out the advantage yet?
There are two benefits to be had with this sizing convention. First, as Jim pointed out, any time he sees a field in a table that does not have one of these sizes, he knows he did not personally add it. Maybe a consultant did, maybe the client, but certainly not him. It's like the parakeet in the coal mine.
Second, it lends itself to consistency. I've set the [FirstName] field size to 16 characters. I've found that to be adequate, knowing that 8 characters is going to be too small and 32 is overkill. Next time I create a [FirstName] field, I will go through the same process and I'll end up at 16 and my next [FirstName] field will be consistent with my last one. Same for [City], which is always 32 and [Email] which is always 64 characters. Consistency! This naming tends to make my field sizing more consistent.
For what it's worth, choosing powers of 2 is arbitrary. One could just as easily use a Fibonacci number series ( 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233) and accomplish the same goals.
Table Naming
Much of what has already been written about field names applies to tables. One thing I omitted in the discussion above is the use of capital letters. I personally prefer to use camel case, with the first letter of words jutting up like camel humps. Some (read Oracle developers here) choose to use all CAPITALS separated by underscores.
This, even more so than conventions already discussed, is a personal matter. However, WE ALL KNOW WHAT IT'S CALLED WHEN YOU WRITE AN EMAIL WITH ALL CAPITAL LETTERS: SHOUTING! Please don't use all capital letters when naming fields and tables ... I may have to work on your database some day and it offends me.
The next thing to consider is whether or not you will use table prefixes. Will your table be named tblEmployee or Employee? I actually don't have a strong feeling about this, but I guess I tend to prefix the table. Maybe because I don't like any ambiguity, and I sometimes use the attribute key word as an alias in my SQL statements, like this ...
SELECT FName + ' ' + LName AS Employee FROM tblEmployee
Finally, we must mention the question of plurals. Is the table tblEmployee or tblEmployees? One record of the table is one employee so the whole table is all the employees. My first inclination is to make table names plural. However, English sometimes sucks and the singular word "Category" does not become "Categorys" but "Categories". "Status" becomes "Statuses". I hate this inconsistency so much that I tend to go singular with table names.
Featured Database Articles
SybaseDecember 8, 2009
Sybase ASE 15: Very Large Storage Systemsby Jeffrey Garbus
Executive Summary:
In this past year, the author has had multiple customers accelerate their migrations to ASE 15 with one goal in mind: taking advantage of Very Large Storage Structures (VLSS) in ASE 15 so that they can increase the size of their growing databases to something with an almost unlimited upside. The idea behind VLSS is that Sybase has modified the ASE system tables to accommodate the larger limitations. In this article old structure, new structure, and practical limitations are discussed.
Introduction
From its inception, Adaptive Server Enterprise (ASE) has been a high-volume Online Transaction Processing (OLTP) or Decision Support System (DSS) or mixed-use database, capable of storing, managing, and retrieving an enormous amount of data.
Over time, the definition of the word “enormous” has changed.
In the early 1990s, we designed and rolled out an application, which contained about 65 gigabytes of data. At the time, our contemporaries wondered if the system would even accommodate a table with 2.5 billon rows of data in a single table (it did). It was, at the time, the 4th largest ASE installation in the world. Anything over 20 gig was considered a Very Large Database (VLDB). Within a few months it had doubled in size, and a few months later doubled again to 250 gig, a monster in those days. The entire project was cost-justified in storage savings: a 2-gigabyte DASD device (for their DB2 applications) cost approximately $40K, while a 2 gigabyte SCSI drive cost about $2K.
Today, you can buy an external 1Terabyte hard drive for under $100. Times change.
In this past year, I have had multiple customers accelerate their migrations to ASE 15 with one goal in mind: taking advantage of Very Large Storage Structures (VLSS) in ASE 15 so that they can increase the size of their growing, 4 terabyte databases to something with an almost unlimited upside. (Yes, famous last words, but with a potential upside of 2 billion devices of 4 terabytes each, I’ll risk eating those words).
The idea behind VLSS is that Sybase has modified the ASE system tables to accommodate the larger limitations.
In this article, we’re going to discuss old structure, new structure, and practical limitations.
Pre-ASE 15 Storage
Prior to ASE 15.0, ASE was limited to 256 logical devices and 32GB for individual devices. Note that when these limits were originally put in place, 20 gig was thought to be a Very Large Database (VLDB), and it was years after before anyone attempted one. In addition, because of an intra-database addressing limitation, an individual database was limited to 4T (if you have a 2K page size) and 8T (if your page size is larger). These limitations were irrespective of physical device or OS-level limitations.
This was driven by the fact that ASE’s storage was organized by virtual pages using a 4 byte bit mask. The virtual page was the mechanism the server used to connect the logical concept of a page with the physical disk. The high order byte of the vdevno column in the sysdevices table was used to encode the device id, and consequently the byte of 8 bits limited ASE to 256 devices (8 bits as a signed integer). (Of course, with one device set aside for master, and perhaps others set aside for tempdb, sysaudits, etc., there were sometimes fewer than 256 available for data). The remaining 3 bytes were used to track the actual virtual page numbers – which considering a 2K page (the storage factor in sysdevices) provided a limit of 32GB per device. Note that theoretically, a 16K server could have large devices, but due the default of 2K and the implementation of sysdevices, a limit of 32GB was imposed.
Here’s a picture of the vdevno column:

Additionally, each database had a limit of 8TB – this was based on 256 devices of 32GB each. But, one database may only have up to 2^31 (2,147,483,648) logical pages, so its maximum size also depends on its logical page size:
2K page server 4TB
4K page server 8TB
8K page server 16TB
16K page server 32TB
Previous limits in early 10 & 11.x timeframes of the numbers of devices per database and device fragments limits were removed a long time ago (they had formerly limited a database to 32 devices. Without the device limit of 32GB, the max database size would be 32TB based on ~2 billion 16K pages.
These limitations caused consternation in a variety of shops with a real need to store database, which at least for today are still considered very big.
Very Large Storage System in ASE 15
In ASE 15, Sybase has implemented what is being called the “Very Large Storage System (VLSS).”
The vdevno/vpageno combined 4-byte integer from the “low” column has been split into separate columns. This has required the rewrite of a significant part of server code; page addresses impact the page number and page header of every physical page – not just the system tables. As a result, ASE now supports ~2 billion devices of 4TB each. It still has the 32,767 limit for the number of databases per server, with a practical limit of roughly 100 due to backup timeframes, etc.
As a result for databases, the upper limit is now driven by the integer representation for pageno and the page size or 32TB as described earlier. The theoretical server size is now 8 million terabytes (8 Exabytes) which unfortunately is limited by the number of databases to 1 Exabyte.
If you have an OLTP in the terabyte range, this is for you (but note the comments later on partitions!). However, if you have a DSS system, you should be giving strong consideration to Sybase IQ.
So:
Devices 231 (2 Billion)
Maximum device size 4TB
Databases/server 32,767
Yields Maximum Storage:
Database size 231 pages * 16KB pg = 32 TB
Theoretical DB storage 32,767 DB’s * 32TB = 1 EB (exabyte) = 1,048,544 TB
Theoretical server size 231 devices * 4TB size = 8,589,934,592 TB
Comparing pre-ASE 15 limits to newer (sic) limits, we get
Attribute Old (12.5.x) Limit New (15.0) Limit
Number of devices 256 2,147,483,648 (2^31)
Maximum device size 32 Gb
32GB ß 224 * 2K vpg 4 Tb
Maximum database size (2K / 4K / 8K / 16K) 4 Tb / ~8 Tb / ~ 8 Tb / ~8 Tb
8TB ß 256 devices * 32GB 4 Tb / 8 Tb / 16 Tb / 32 Tb
Not bad; pre-15, an entire database/server could only take up 4 Tb; with ASE 15, we can have 2 billion devices of that size.
In ASE 15.0, the virtual page number is represented by two 32-bit values. One is the device number; the other is the block number
A Word on Partitions
Storing the data is half the battle. Maybe a third.
The rest of the battle involves data manipulation and maintenance.
When you insert a row, how does the server know where the next empty page is? When you retrieve a row, how long will a table scan take? How do you backup a 10Tb database? Run dbcc? Update your statistics?
Databases in the terabyte range are nontrivial to manage at this point in history. (In another decade, they’ll fit in my wristwatch). For today, we need to plan a bit.
With the advent of ASE 15, Sybase has added real semantic partition management to Adaptive Server Enterprise. This means that you can separate your data into a variety of partitioning schemes (subject of a separate article).
Partitioning, though, is extremely relevant to large tables (which tend to go along with large databases), because of everything from insertion rates to data archival.
Partitioning nets you:
• Partitioned indexes, which yields faster access performance, smaller index structures, and improved parallel search.
• Partitioned data, which allows you to organize the data based upon your own rules (hash, data range, list partitioning, round-robin partitioning), which lets you either spread io across multiple LUNs, or to allow archiving to hit only one of several LUNs, without interfering with online access.
• Partition-aware maintenance, which lets you (for example) update statistics or run dbcc on only the more recent partitions. You can also truncate, reorg, or bcp on a partition basis.














.PNG)
